About Worksets
Scholars rely on library collections to support their scholarship. Out of these collections, scholars select, organize, and refine the worksets that will answer to their particular research objectives. The requirements for those worksets are becoming increasingly sophisticated and complex, both as humanities scholarship has become more interdisciplinary and as it has become more digital. The HathiTrust is a repository that centrally collects image and text representations of library holdings digitized by the Google Books project and other mass-digitization efforts.
The HathiTrust’s computational infrastructure is being built to support large-scale manipulation and preservation of these representations, but it organizes them according to catalog records that were created to enable users to find books in a building or to make high-level generalizations about duplicate holdings across libraries, etc. These catalog records were never meant to support the granularity of sorting and selection or works that scholars now expect, much less page-level or chapter-level sorting and selection out of a corpus of billions of pages.
The ability to slice through a massive corpus consisting of many different library collections, and out of that to construct the precise workset required for a particular scholarly investigation, is the “game changing” potential of the HathiTrust; understanding how to do that is a research problem, and one that is keenly of interest to the HathiTrust Research Center (HTRC), since we believe that scholarship begins with the selection of appropriate resources.
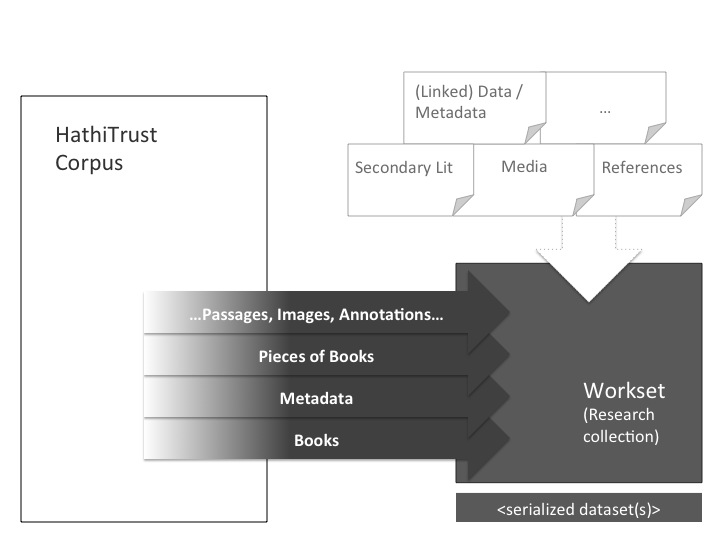
Conceptualizing an HTRC Workset
The workset is a type of collection created by scholars for their research. It is specialized to the HathiTrust context and intended to facilitate computational analysis. In many current approaches to information systems that support scholarly research, collections have not received a level of development and tool creation to match the attention given to the individual resources that collections organize. The HathiTrust corpus presents unique opportunities for the development of tools and techniques to conduct humanities research. Providing for the creation and use of worksets based on the corpus will allow a unique level of support for the practices of humanities researchers.